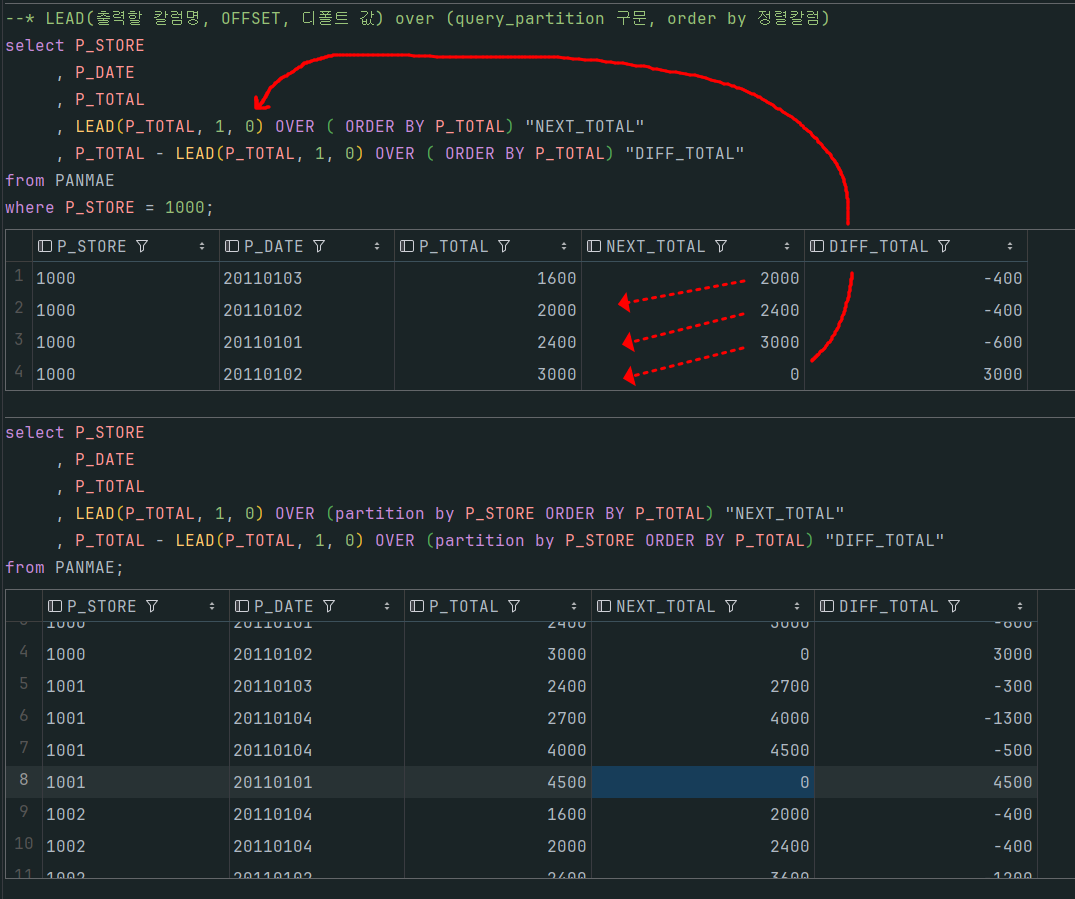
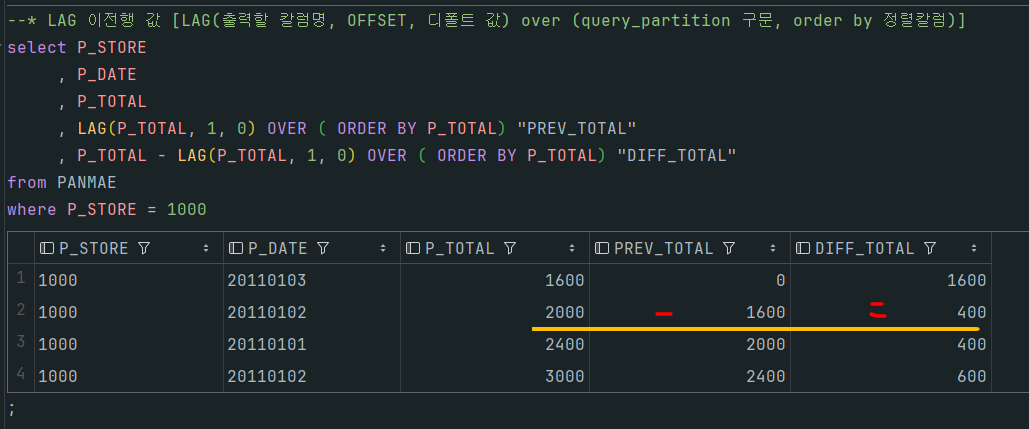
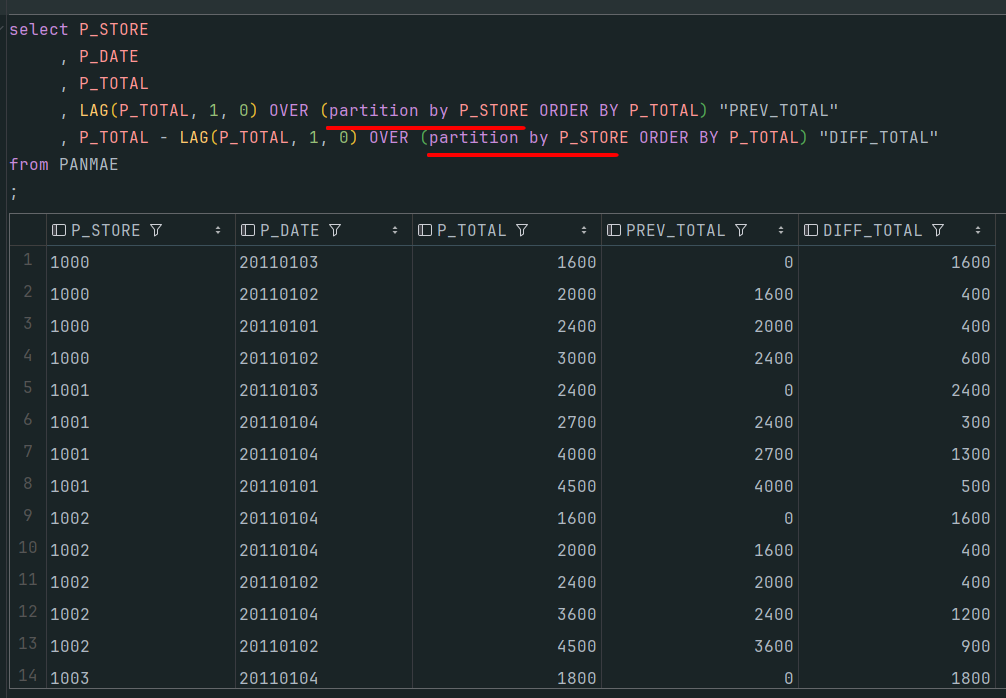
공부를 하다 시간이없어 바로 벌크 쿼리를 야생형으로 공부해보았다.
미래의 나를 위해 정리를 해보자
우선.
벌크 쿼리란?
단순하게 10개의 데이터를 DB에 넣어야할때,
10번을 나눠넣냐 1번으로 넣냐 이렇게 생각하면 쉽다(수정도 마찬가지)
좀더 쉽게 예를들면
엑셀에서 10,000개의 행을 읽었을때 과연 나는 for 문을 돌면서 10,000 번 insert 를 해야할때
부담을 느낄 수 밖게 없다.
이럴때 쓰는게 벌크 쿼리이다.
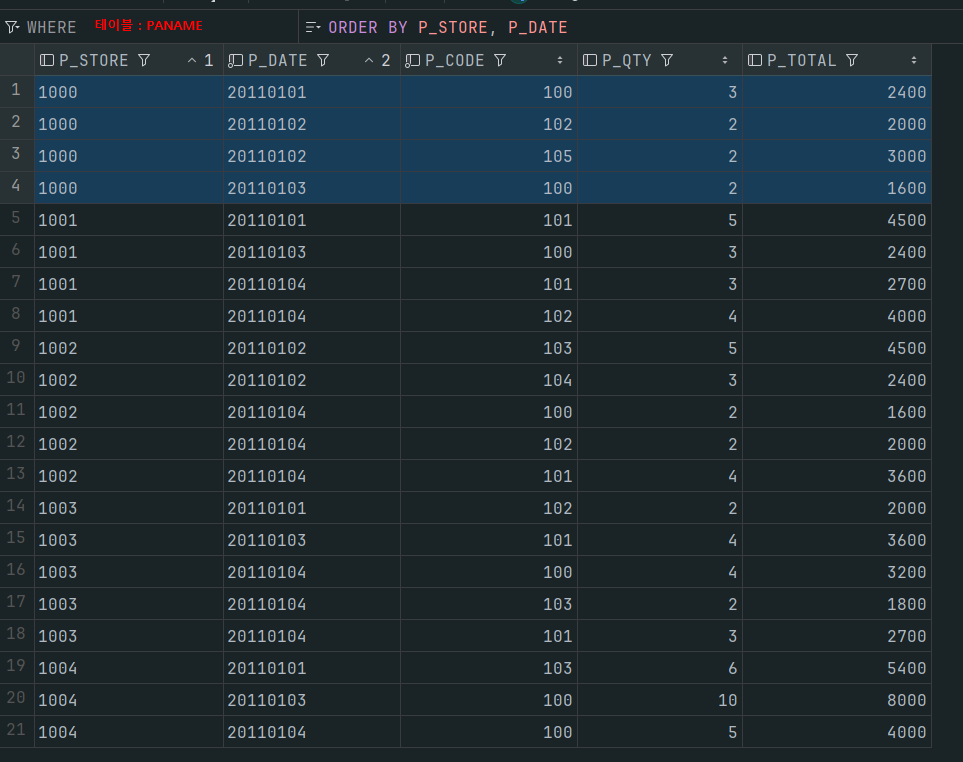
다음과 같이 테스트 하기위해서 테이블을 만들었다.
여기다 insert 할 것이다.

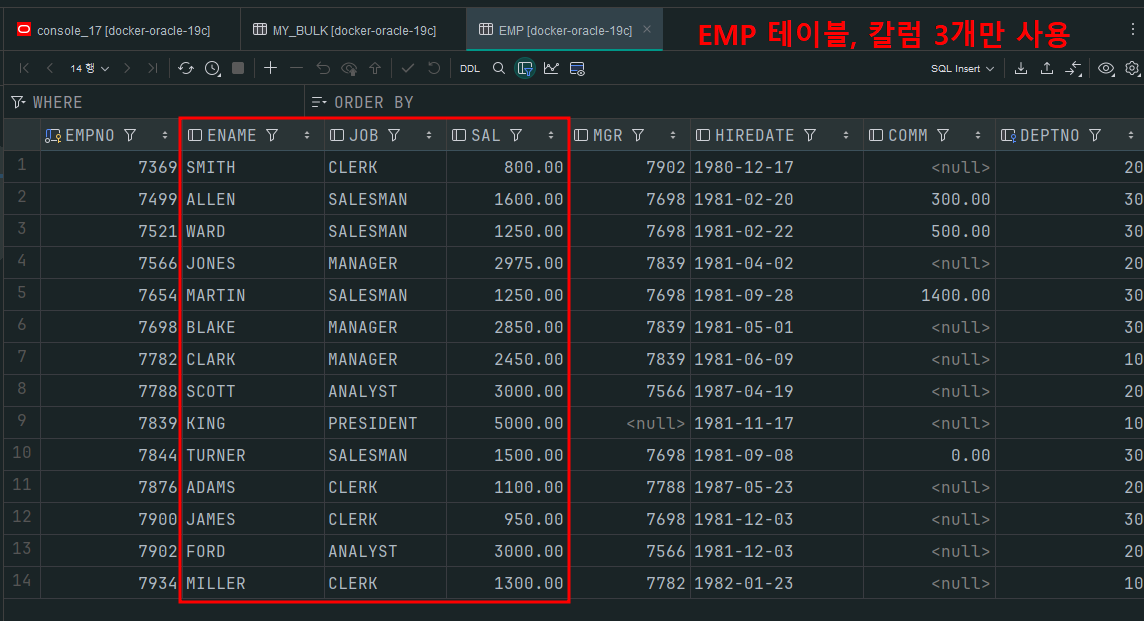
그리고 데이터가 있는 테이블을 하나 정했는데 다음과 같으며
딱 3개의 칼럼만 사용할 것이니 부담없이 보자
ename, job, sal
이제 PL / SQL 문을 알아볼것인데
이는 하나의 프로그래밍 언어 레벨로 이해하면된다.
따라서 반복문, 조건문, 예외처리 같은 문법들도 사용할 수 있다.
심플하게 문법을 알아보자
구조는 다음 과 같다
DECLARE (1)
...
BEGIN (2)
...
END;
(1) 영역 :
타입을 선언하고, 변수에 타입을 바인딩한다
자바로 비유하면 인스턴스 멤버들을 정의한다, 즉 String 이라는 타입을 정의하고, name 이라는 필드에 타입을 바인딩한다. 결론은 String name; 을 만드는것이다. 이때 초기화도 직접해줄수 있다
또 자바에서도 다른 클래스를 타입으로 가질수있는데 private Book book, private Contents contents 이런식으로
이또한 가능하다
사진으로 이해해보자
EMP 테이블의 하나의 로우를 타입으로 갖는 "타입"을 정의하고
l_emp 라는 변수가 그 "타입"이라고 정의했다.
EMP 테이블의 레코드가 타입이라는건 EMP%ROWTYPE 이라고 작성한다

만약 String name, int age 처럼 하나의 칼럼만 정의하고싶다면
이렇게 하면된다
EMP.job%TYPE => EMP 테이블의 job 칼럼의 타입을 사용한다

만약에 초기화를 직접 하고싶다면
이런식의 문법으로 하면된다
여기서 주의할게 죄다 List 처럼 컬렉션이라고 생각하면 편안하다

이제 begin ~ end 문은 실제 동작할 부분을 작성하는 곳인데 좀더 봐야한다 .
예제를 보면서 감을 익히자
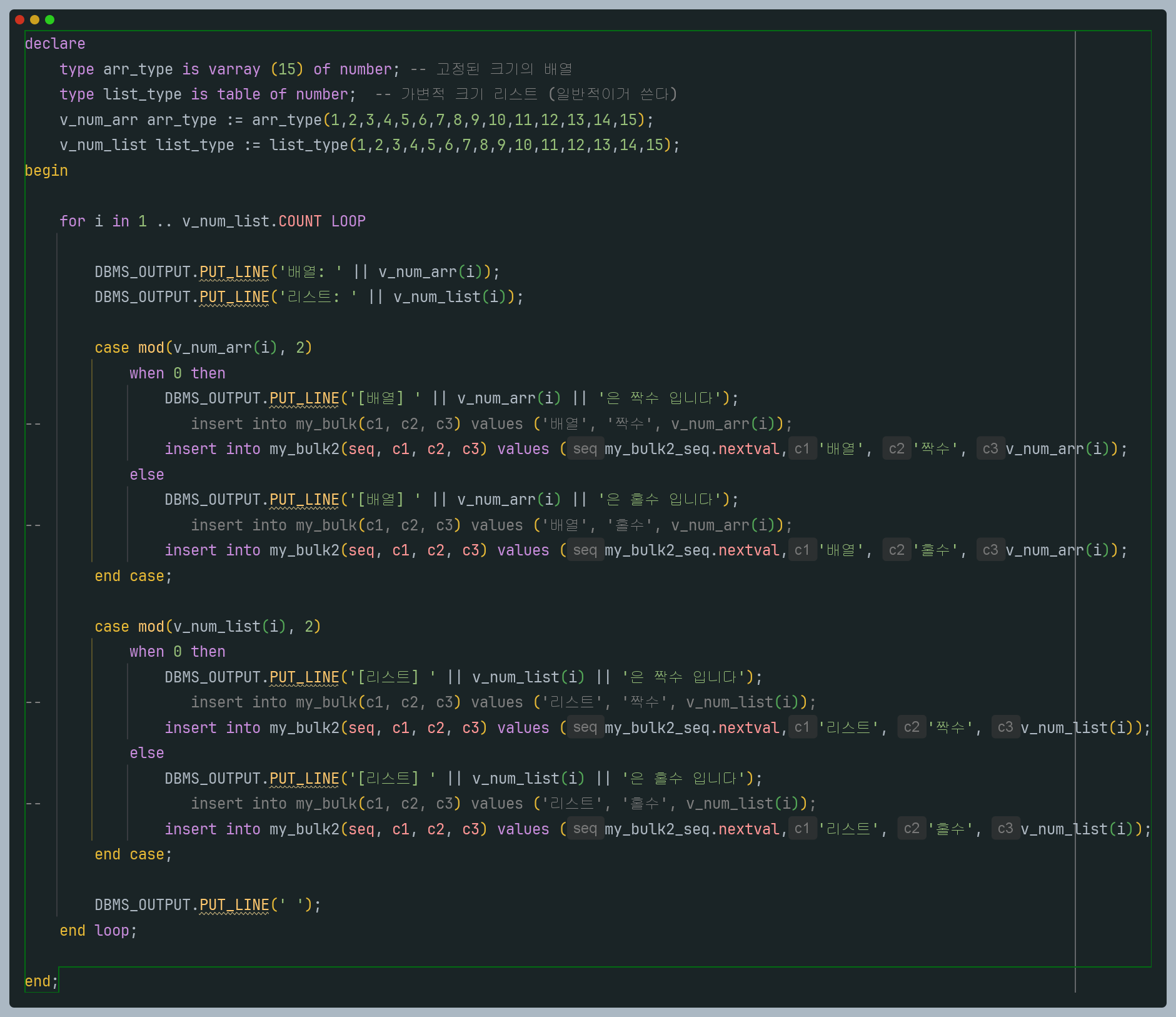
첫번째 예제 - insert + 단순
1. 숫자 15개를 채울 수 있는 배열을 만든다
2. 숫자 15개를 채울 수 있는 리스트를 만든다
3. 반복문을 돌면서 각각 출력해본다
4. 각 루프 마다 값이 짝수나 홀수이면
"배열", "짝/홀수", "값" , "리스트","짝/홀수", "값"
이런식으로 my_bulk 테이블에 insert 한다

출력은 DBMS.OUTPUT.PUT_LINE() 을 이용하면 된다
실제 출력 결과는 다음처럼 나왓다
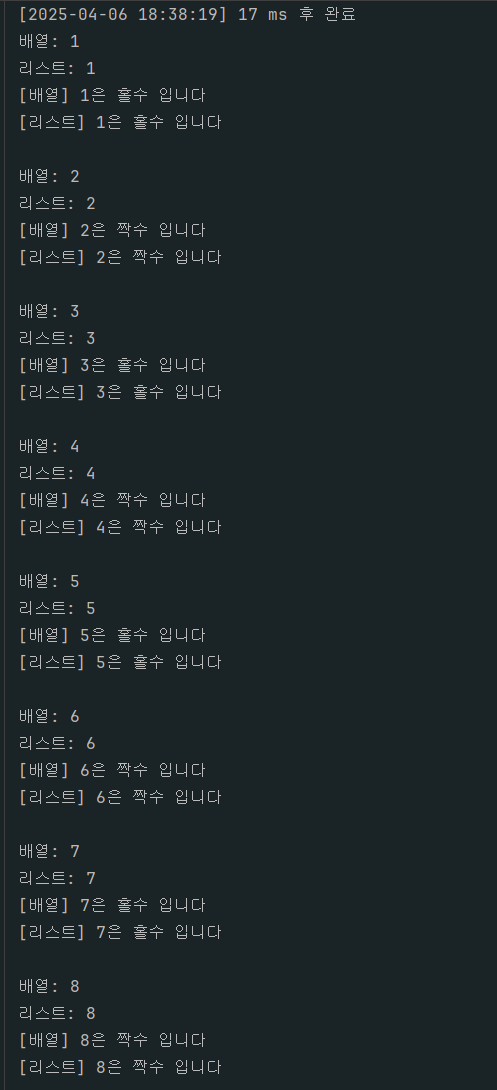
my_bulk 테이블은 다음과같이 데이터가 들어왔다

잘들어왔다
지금 상황은
직접 값을 정의한다음 그 값을 반복문과 조건문을 써서 insert 한 경우이다
두번째 예제 - Update
미안하다,
PK 가 필요해서 두번째 테이블을 만들었다... (update 벌크쿼리를 위해)

우선 아까 만든 PL/SQL 에 한줄씩 추가해서 기본데이터가 들어가게 만들었다
자 이제 pk도 있겠다. 준비는 되었다
update 벌크 쿼리에 대해서 알아보자

여기서부턴 좀 자세히 알아볼건데
세가지 유형을 알아볼건데, update 상황에서 이를 알아보자 (insert문도 가능)
첫번째 유형 - 기존 방식
두번째 유형 - CURSOR 방식
세번쨰 유형 - FORALL 방식
1. 기존 방식
insert 에서 하던 방식인데 결국 이와 비슷하다 볼 수 있다
여기서 update 쿼리를 날리진 않았지만 DB 를 더 괴롭히는 방식이라고 볼 수있다

결과는 다음과 같다

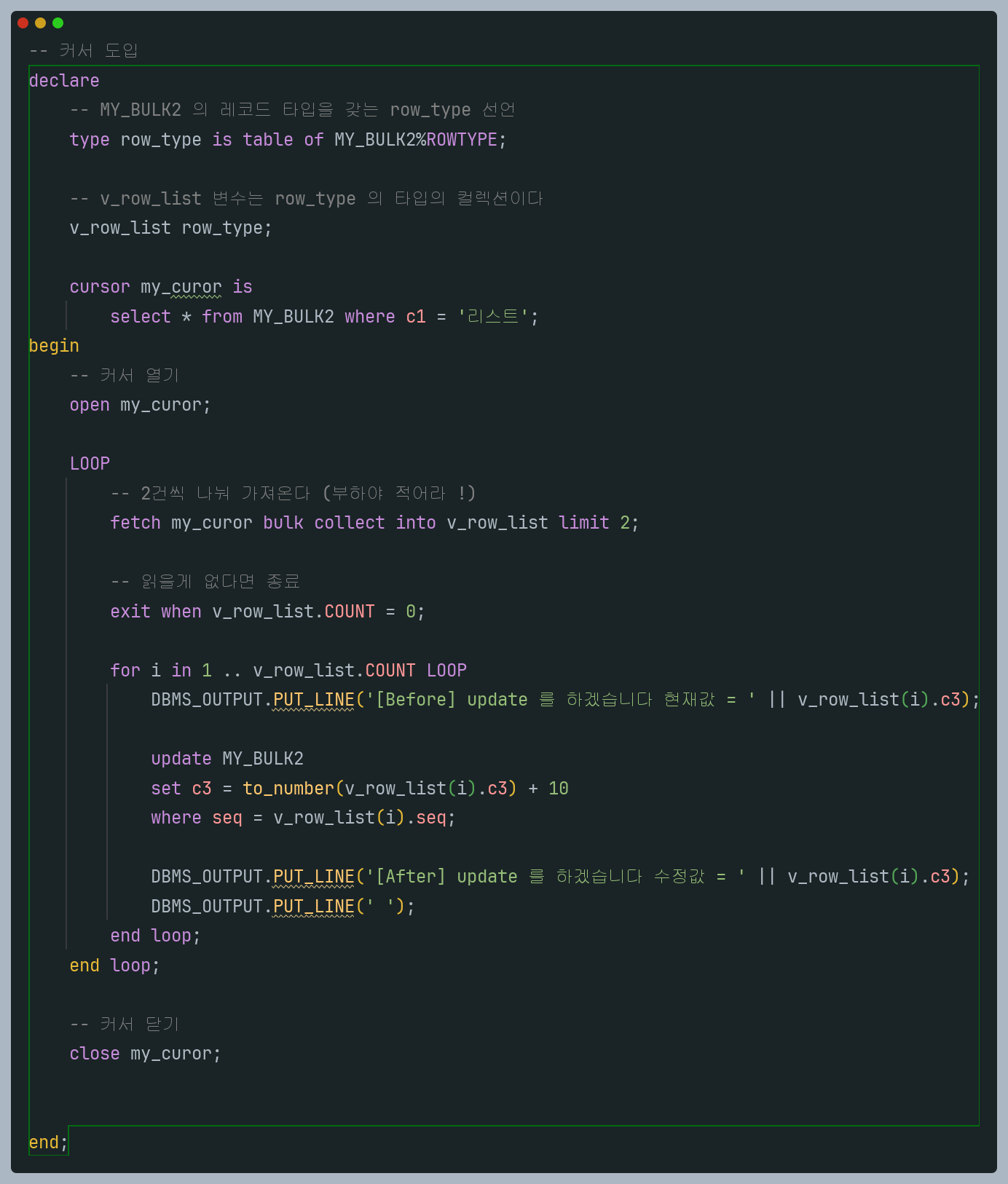
2. CURSOR 도입
자바를 공부했다면 JDBC 를 가지고 JAVA로만 직접 select 를하고
결과셋을 가지고 반복문 돌면서 데이터를 다룬적이 있을 것이다 그때도 CURSOR (커서) 를 이용하는데
그와 같은 개념이다 (포인터)
언제사용하는가? 소량의 데이터에는 적합하다. 대량의 데이터는 FORALL 문을 써야한다
커서는 루프마다 실제 쿼리가 나간다,
즉 에러가나면 그 루프에서 멈추고 이전까지 작업된 내용은 반영되어있다.
다음은 c1 칼럼값이 리스트인 데이터들을 2건씩 가져와서
c3 값을 10씩 증가시키는 PL / SQL 문이다
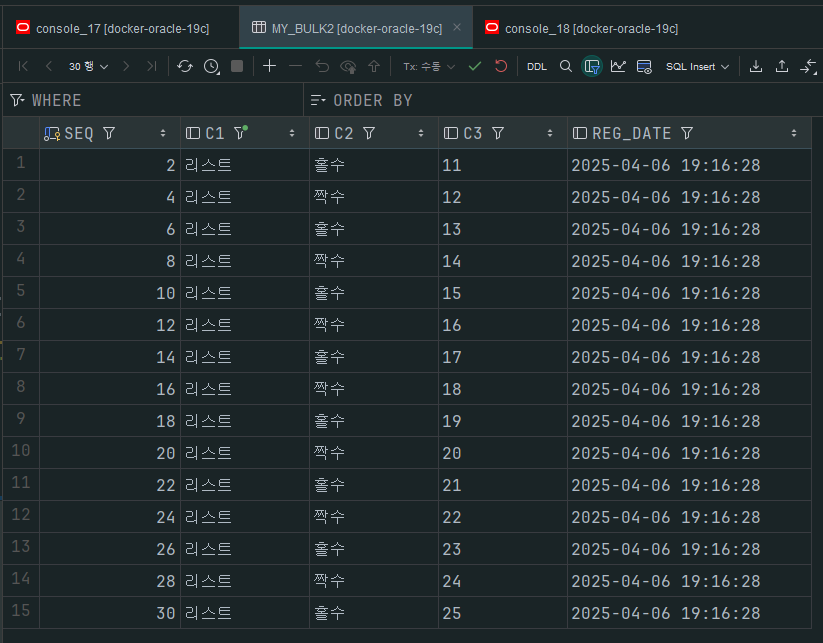
기존 데이터

결과 데이터
3. FORALL 도입
FORALL 을 사용하면 커서때와 다르게
JPA 처럼 SQL 쓰기저장소에 쭉쭉쌓였다가 마지막 한번에 나간다.
즉, 1번만 나간다고 생각하면된다 따라서 대용량 데이터 작업에 유용하다.
또한 원자성을 지키기 때문에 하나라도 실패하면 전체 실패하게된다.
전체 실패, 전체 성공 두개뿐이다.
주의할게 있는데 FORALL 내에서는 insert, update, delete 문을 쓸수있고
for문처럼 콘솔에 찍는것은 할 수 없다 for문에서 해야한다.
그리고 순회하는 타입도 레코드형이면안되고 단순 타입이어야한다
자바로 비유하면 List<Book> 은 안된다 (커서쓸때는 가능)
List<String> , List<Integer> 형태만 된다 .
코드는 좀더 짧아졌다.
앞으로 테이블 결과는 10씩 증가되는거니 생략하겠다.

3. CURSOR + FORALL 조합
인간의 욕심은 끝도없다
아무리 한방이 좋다해도 메모리가 부담될 수 있다.
이때는 커서와 조합해서 써야한다
하지만 역시 주의할게. 트랜잭션 단위이다
만약 forall 를 loop 가 감싸고있다면 이 루프 갯수만큼 트랜잭션이 있는 것이다.
따라서 savepoint 가 필요하고, 예외처리도 필요하다.

'데이터베이스 > Oracle' 카테고리의 다른 글
| ORACLE - SUM 함수의 다른 활용법 (0) | 2025.01.28 |
|---|---|
| ORACLE - LEAD 함수 : 다음 행의 값을 가져온다 (1) | 2025.01.28 |
| ORACLE - LAG 함수 : 이전 행의 값을 가져온다 (0) | 2025.01.28 |
| ORACLE - RANK 함수 (0) | 2025.01.28 |
| ORACLE - PIVOT, UNPIVOT (0) | 2025.01.26 |